Cryo-ET subtomogram averaging to 3.99 A, on spot, in your own AWS
Two halves of the RELION-5 cryo-ET pipeline (EMPIAR-10164 immature HIV-1 VLPs) on spot GPUs in a customer's own AWS: AreTomo2 markerless alignment + reconstruction in 192 s on one T4, and a gold-standard subtomogram-averaging refine that re-runs the tutorial's final step (from its published alignments and reference) to a 3.99 A Gag lattice for ~$2.2 of spot GPU. Demonstrated independently; scoped honestly below.
Two halves of the canonical RELION-5 cryo-ET pipeline — EMPIAR-10164, immature HIV-1 Gag virus-like particles — on commodity spot GPUs in the customer's own AWS account, demonstrated independently. AreTomo2 does markerless tilt-series alignment and tomogram reconstruction in 192 s on a single T4. Separately, starting from the tutorial's published alignments, particle picks, and reference map, a gold-standard subtomogram-averaging refine lands the immature Gag lattice at a 3.99 A FSC resolution in ~1.65 h on four T4s for ~$2.2 of spot GPU. We did not chain the two — see Honest scope. No HPC engineer, no data egress, and the run parameters, cost, and outputs accreting as a queryable record in the account.
Companion to the single-particle RELION cryo-EM post — same operating model (managed Slurm, customer's AWS, spot economics), the tomography sibling workload. Cryo-ET is the harder of the two to operate: it needs a different front half (tilt-series alignment + reconstruction) that single-particle pipelines don't.
TL;DR (June 4 2026)
- Dataset: EMPIAR-10164, immature HIV-1 dMACANC VLPs — the dataset the RELION-5 tomography tutorial is built on. Five tilt series; the immature Gag/CA-SP1 lattice is the recognized hero structure (published to ~4 A).
- Front half (AreTomo2): markerless tilt-series alignment + weighted-back-projection tomogram reconstruction of
TS_01(raw 4k x 4k x 41-tilt stack, 2.3 GB) in 192 s on a single spot T4, output binned 6x to a 638 x 618 x 332 inspection-grade tomogram with the immature VLPs clearly resolved. The RELION CUDA image we run doesn't bundle AreTomo2, so we staged the AreTomo2 CUDA-12 binary onto the cluster filesystem and ran it under the RELION CUDA runtime. - Back half (subtomogram averaging): this is a re-run of the tutorial's final averaging step, not an independent determination — we took the published tilt-series alignments, particle picks, and a published reference half-map, regenerated the pseudo-subtomograms ourselves (
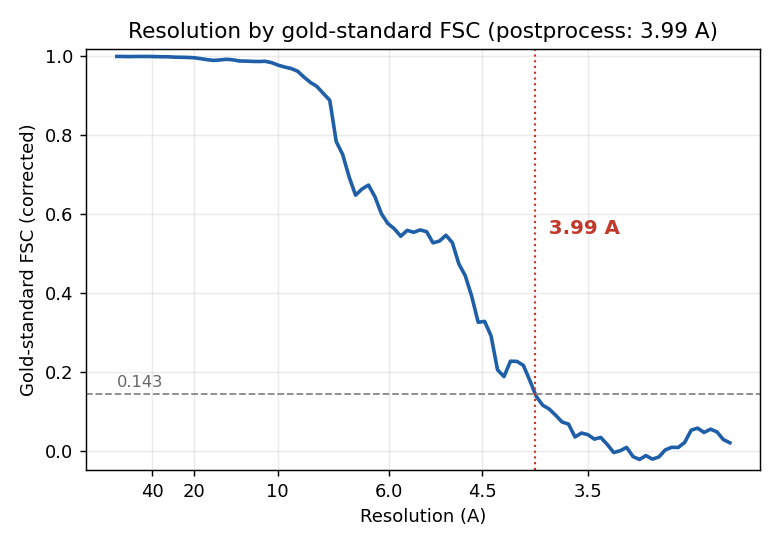
relion_tomo_subtomo, 9,442 particles, box 512 / crop 192), and ran a gold-standardrelion_refineauto-refine (C6) +relion_postprocess. Final resolution 3.99 A (FSC = 0.143, B-factor -101.6 A^2). The refine started from the published reference low-pass-filtered to 5.5 A (--ini_high 5.5) — see Honest scope on reference bias. - Multi-GPU: the refine converged in 17 iterations, ~1.65 h on 4x T4 (single node,
mpirun -n 5, 4 ranks 1:1 on 4 GPUs). The same job on 1x T4 did ~26 min/iteration and timed out at iteration 11 in 5 h — ~5.6x faster per iteration, n=1 each. That number exceeds 4x, so it isn't pure GPU scaling: the single T4 was almost certainly I/O-/host-RAM-bound on the particle working set, which the 4-GPU box's larger aggregate RAM and NVMe relieves. The honest takeaway isn't a clean scaling factor — it's that four GPUs finished and one didn't. - Cost: the converged 3.99 A structure cost ~$2.2 of spot GPU (4x T4
g4dn.12xlargeat $1.35/hr x ~1.65 h), plus a few cents for the CPU subtomogram extraction. - A real spot wrinkle, kept in: our first attempts pinned A10G GPUs and hung — g5 spot was momentarily exhausted in the cluster's AZs and the account's on-demand GPU quota was zero, so there was no fallback. Relaxing the request from "an A10G" to "any NVIDIA GPU" let the scheduler grab T4s and the run proceeded.
- n: the 3.99 A refine is n=1. The 1x-vs-4x scaling is one run each on identical inputs. The front-half AreTomo2 run is
TS_01only (1 of 5 tilt series).
What cryo-ET actually demands
Single-particle cryo-EM and cryo-electron tomography share a final engine — RELION's relion_refine — but everything before it is different. Tomography starts from a tilt series: dozens of images of the same field taken at different stage tilts. Before you can average anything you have to (1) align those tilts into a consistent geometry and (2) back-project them into a 3D tomogram. Historically that meant gold fiducial markers and hours of manual IMOD work. AreTomo2 replaced the manual step with GPU-accelerated markerless alignment, which is what makes the pipeline batchable at all.
RELION-5 wraps AreTomo2 (and IMOD, CTFFIND4, cryoCARE) for exactly this front half, then extracts pseudo-subtomograms — CTF-pre-multiplied 2D stacks cropped from the tilt images at each particle position — and feeds them to the same gold-standard relion_refine used for single particles. Our job was to prove both halves run cleanly in a customer's AWS account on spot GPUs, and to land the recognized hero number.
The front half: AreTomo2 on spot
AreTomo2 is a single CUDA binary, not part of any RELION container we run. The cluster's compute nodes can't build container images (unprivileged slurmd), but they can pull a prebuilt binary onto the shared filesystem and execute it — the same pattern we use for other GPU tools. We downloaded the official AreTomo2_1.1.2_Cuda121 build, dropped it on EFS, and ran it inside the RELION CUDA-12.6 runtime so the CUDA libraries resolved:
AreTomo2 -InMrc TS_01.mrc -OutMrc TS_01_aretomo.mrc -AngFile TS_01.rawtlt \
-VolZ 2000 -OutBin 6 -Patch 0 0 -Gpu 0 -Wbp 1 -PixSize 1.35 -FlipVol 1 -OutImod 1
On one spot T4 the whole thing — markerless alignment of all 41 tilts, then weighted-back-projection reconstruction of a 638 x 618 x 332 tomogram (binned 6x, an inspection-grade volume for picking/visualization — subtomogram averaging works from the un-binned tilt images, not this volume) — took 192 seconds. The immature VLPs are immediately visible as membrane vesicles in the reconstruction:
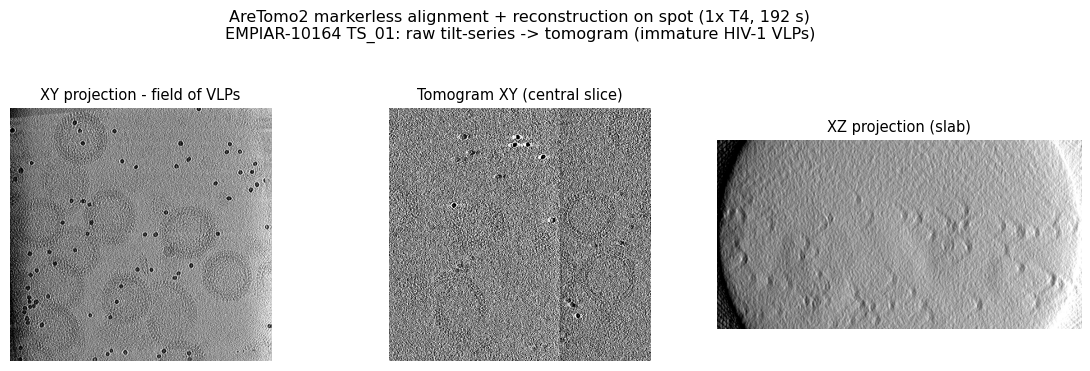
That is the catalog gap closed: from a raw tilt-series stack to a usable tomogram, on a commodity spot GPU, in three minutes, with no fiducial picking and no manual alignment.
The back half: subtomogram averaging to 3.99 A
For the averaging hero we used the tutorial's published tilt-series alignments, curated particle positions, and reference half-map (see Honest scope on reference bias), regenerated the pseudo-subtomograms ourselves, and ran the gold-standard refine verbatim — starting from that reference low-pass-filtered to 5.5 A:
relion_refine_mpi --auto_refine --split_random_halves \
--ios optimisation_set.star --ref half1.mrc --solvent_mask mask_align.mrc \
--particle_diameter 230 --sym C6 --ini_high 5.5 --healpix_order 4 \
--ctf --solvent_correct_fsc --pad 2 --gpu
launched as mpirun -n 5 (1 leader + 4 half-set/GPU workers — gold-standard refine needs at least three ranks). It converged in 17 iterations. relion_postprocess with the FSC mask and automatic B-factor sharpening puts the final resolution at 3.99 A:
The averaged density is a recognizable immature Gag shell. C6 symmetry was imposed during the refine (--sym C6), so it is not independent evidence of a hexameric lattice; at this rendering the max-Z projection shows the ring-like organization of the symmetrized shell and the orthogonal slices its layered density:
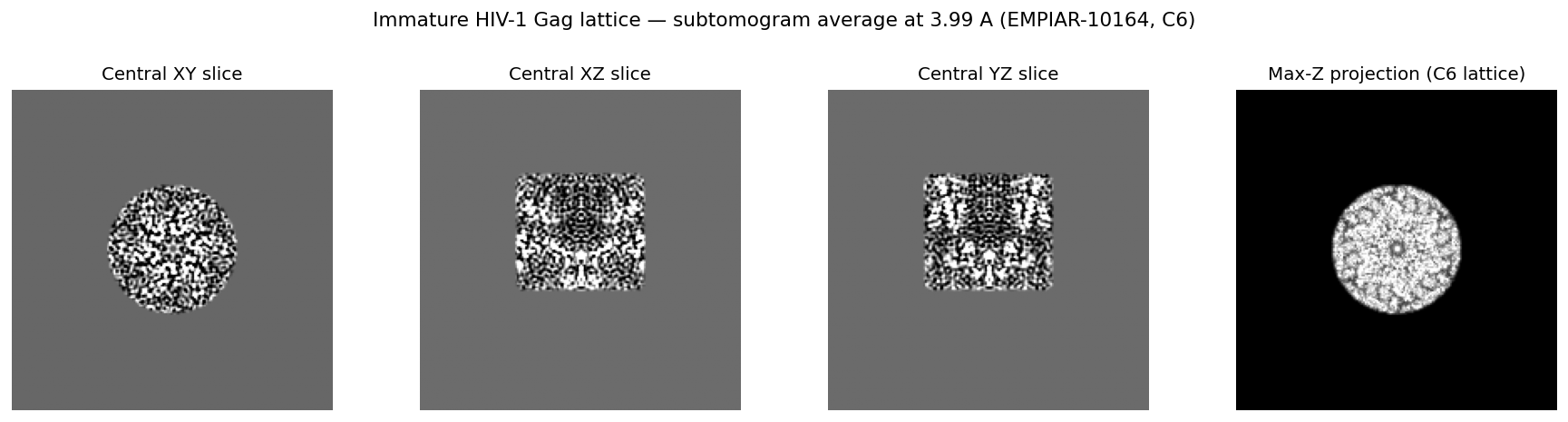
This re-runs the tutorial's final averaging step in full on our managed spot substrate and lands the published resolution (~4 A; 3.99 A here) — confirming that the engine and our orchestration are correct and cheap, not an independent redetermination of the structure.
Single GPU vs four: the operating difference
Subtomogram averaging is GPU-bound and gets more expensive per iteration as it refines (the working image size grows as resolution improves). On one T4 each iteration took ~26 minutes, and the run hit our 5-hour wall-clock cap at iteration 11 — it never produced a structure. On four T4s of a single node, each iteration took ~4.6 minutes and the whole refine converged in ~1.65 h. Same data, same parameters:
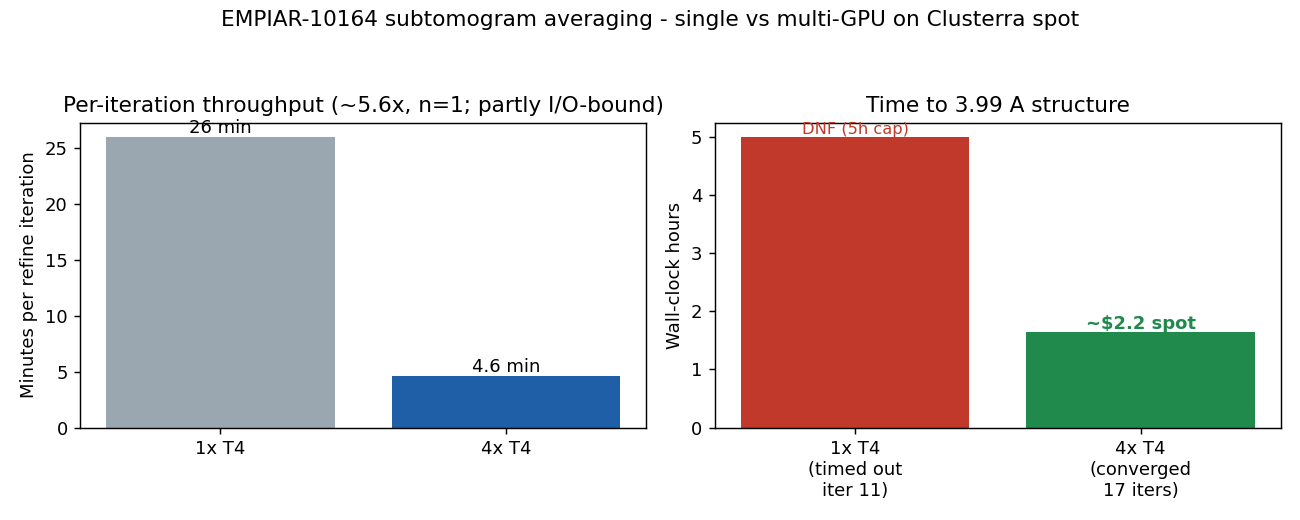
The ~5.6x per-iteration gap exceeds 4x, so it is not pure GPU-compute scaling — the single T4 was almost certainly I/O-/host-memory-bound on the particle working set, a bottleneck the 4-GPU node's larger aggregate RAM and NVMe bandwidth relieves. With n=1 each, don't read it as a precise factor. The point that survives the caveats: four GPUs produced a 3.99 A structure by lunchtime and one GPU never finished. This is single-node multi-GPU MPI inside our containerized Slurm; no cross-node networking, no EFA, just four GPUs on one spot box.
The spot reality, not airbrushed
The first refine attempts asked Slurm for A10G GPUs and sat in PENDING with no node ever appearing. The cause was two compounding facts about the account: g5 (A10G) spot capacity was momentarily unavailable in the AZs the cluster spans, and the account's on-demand GPU vCPU quota was zero, so there was no on-demand fallback to rescue the spot shortage. Pinning a specific GPU family turned a transient capacity dip into an indefinite hang.
The fix was to stop over-specifying: request a GPU rather than an A10G, and let the scheduler take whatever NVIDIA capacity exists — which at that moment was T4s. One line, and the work proceeded. The durable fixes (raise the on-demand GPU quota; widen the cluster's availability zones) are account-level settings, but the point stands: the managed layer turned an infrastructure papercut into a parameter, instead of a support ticket. We left the T4s in the headline numbers rather than re-running on faster GPUs once capacity returned — the story is about operating on whatever spot gives you, cheaply.
Honest scope
- The 3.99 A average used the tutorial's upstream alignments and particle picks. We regenerated the subtomograms and ran the gold-standard refine + postprocess ourselves on spot, so the result is genuinely re-run by us — but the tilt-series alignment and the particle curation behind that specific number came from the published RELION-5 workspace, not from our AreTomo2 run. Particle picking and class curation are the human-in-the-loop seams of cryo-ET; we did not automate them, and we don't claim to.
- The refine started from a published, near-final reference map (
Reconstruct/bin1reference/half1.mrc), low-pass-filtered to 5.5 A (--ini_high 5.5). Starting a refine from a high-resolution reference of the same structure is the textbook reference-bias ("Einstein-from-noise") concern. Gold-standard half-set FSC and a sufficiently low-pass-filtered reference are the standard guards, and they're what the tutorial protocol uses — but the honest reading is that this is a pipeline-correctness reproduction, not a from-scratch determination immune to model bias. We make no novel-structure claim. - The AreTomo2 front half was demonstrated on one tilt series (
TS_01), not chained into a fresh 3.99 A. It proves the alignment + reconstruction step runs correctly and fast in our environment. Closing the loop — AreTomo2 across all five tilt series, re-picking, and re-refining to an independent resolution — is more processing than this write-up covers, and is the work that would let us drop the "from the tutorial's inputs" caveats above. - GPUs were T4s, not A10Gs, because of the spot/quota situation above. A10G or L40S would be faster; the numbers here are a floor, not a ceiling.
- n = 1 for the converged refine; the scaling comparison is one run per configuration on identical inputs. Treat the wall-clock and cost as representative single observations, not distributions.
- No custom container yet. We stitched the cached RELION 5.0 image, a staged AreTomo2 binary, and the host CUDA runtime. A packaged
relion-tomoimage (RELION-5 + IMOD + AreTomo2 + CTFFIND4) and first-classrelion-tomo-align/relion-tomo-statemplates are the obvious next step; this run is the evidence they're worth building.
Reproduce it
- Data: EMPIAR-10164 (immature HIV-1 dMACANC VLPs). The precomputed RELION-5 tutorial workspace is on Zenodo, DOI 10.5281/zenodo.11068319 (
relion-5-sta-results.tar.gz, 29.5 GB) — it ships tomograms, masks, references, motion-corrected tilt images, and metadata, but strips the heavy subtomogram.mrcsstacks, which is why the extract step regenerates them. - Front half (AreTomo2): binary
AreTomo2_1.1.2_Cuda121from the AreTomo2 release, staged to EFS and run under the RELION CUDA-12.6 SIF; the exact command is in The front half above. ~3 min, 1x T4. - Back half:
relion_tomo_subtomo(box 512 / crop 192 / bin 1, max-dose 50,--float16 --stack2d) thenrelion_refine_mpi --auto_refine --split_random_halves --ios <opt_set> --ref <half1> --solvent_mask <mask> --particle_diameter 230 --sym C6 --ini_high 5.5 --healpix_order 4 --pad 2 --ctf --solvent_correct_fsc --gpu, launchedmpirun -n 5(gold-standard refine needs ≥3 ranks), thenrelion_postprocess --auto_bfac true. - Compute: 4x T4 (
g4dn.12xlargespot, $1.35/hr), ~1.65 h, ~$2.2. Single-T4 contrast ong4dn.xlarge. - These ran as plain Slurm jobs on the managed cluster; the same parameter surface is now packaged as the
relion-tomo-alignandrelion-tomo-statemplates.
The operating model
Everything above ran in the customer's own AWS account: GPUs are spot instances that the managed control plane requests and releases; the 30 GB working set lived on the account's EFS; the tilt series and maps never left the account. The control plane carries the run parameters, the instance type, the spot price, and the output paths as a queryable record — so "what did the 3.99 A run cost and what command produced it" is a lookup, not an archaeology project.
That is the bet: cryo-ET is batchable enough to live on managed spot Slurm, the front half (AreTomo2 alignment + reconstruction) is fast and cheap, the back half is the same RELION engine we already operate, and the whole thing fits a single multi-GPU node for the datasets a Series-A structural-biology team actually has. The hard novel structures still need a human; the recognized benchmark, reproduced for a couple of dollars in your own account, does not.